
| Getting your Trinity Audio player ready... |
Facebook(2004年設立)やTwitter(2006年設立)の台頭と、それに伴う二極化の進展は、ここ数年、話題になっている。議論の基本は、常に利益と二極化のバランスを取ることにあるようだ。
二極化を是正する方法として、活動家、専門家、利益団体、政府代表者などから、規制、透明性、教育の分野に変化をもたらすという解決策が提案されています。
しかし、本当の解決策は簡単で、酔った状態でスクロールを開始することです。
ソーシャルメディア分極化仮説
ソーシャルメディアと二極化に関する多くの研究論文の一般的な仮説は、通常、これらの企業の主な目的が株主のためにお金を稼ぐことであるという事実に焦点を当てています。
エンゲージメントやユーザーの利用時間を増やしたいというソーシャルメディア企業の利益動機と、最もエンゲージメントを生むコンテンツを優先的に宣伝するアルゴリズムの最適化が相まって、ソーシャルメディア上で偏った視点が強化・拡散され、結果として偏った社会になっているのです。
しかし、アルゴリズムとはいったい何なのだろうか。また、フェイスブックのアルゴリズムは、ネット上の憎しみを煽りながら、どのようにお金を稼いでいるのでしょうか?
アルゴリズムとは何ですか?
アルゴリズムとは、ある問題を解決したり、課題を達成したりするための一連の指示や手順に従ったものです。生物学、医学、金融など様々な分野でアルゴリズムが活用されている。生物学では、研究者が遺伝子のデータを分析し、異なる遺伝子の機能を理解するためにアルゴリズムを使用しています。医学の分野では、医師が医療画像を解析し、診断に役立てるためにアルゴリズムが使われています。金融の分野では、金融モデリングやリスク管理などの業務にアルゴリズムが利用されています。これらの分野における具体的なアルゴリズムの例としては、医療診断における決定木アルゴリズム、遺伝学研究における遺伝子配列アライメントのアルゴリズム、ファイナンスにおけるポートフォリオ最適化のアルゴリズムなどがある。
アルゴリズムにはどのような種類があるのですか?
アルゴリズムには様々な種類がありますが、ここでは現在使われている最も一般的なアルゴリズムを紹介します。
- 検索アルゴリズム。文書中の特定の単語を探したり、電子商取引のデータベースから特定の商品を探したりするなど、大規模なデータセットから特定の項目を見つけ出すアルゴリズムです。例えば、線形探索やバイナリサーチなどがある。
- 並べ替えアルゴリズム。アルファベット順や数値順など、特定の順序でデータを整理するアルゴリズム。バブルソート、挿入ソート、クイックソートなどがある。
- 機械学習アルゴリズム。これらのアルゴリズムは、コンピュータシステムがデータから学習し、明示的にプログラムされることなく予測や決定を行うよう訓練します。例えば、線形回帰、決定木、ニューラルネットワークなどがある。
- グラフアルゴリズム。グラフで表現されたデータを処理するアルゴリズム。例えば、グラフ内の2点間の最短経路を求めるアルゴリズムや、グラフの最小木(スパニングツリー)を求めるアルゴリズムなどがある。
- ランダム化アルゴリズム。決定論的なアルゴリズムが見つからない場合や、確率的なアプローチが望ましい場合に使用されます。例として、モンテカルロ法、ランダム化クイックソートなどがある。
- 近似アルゴリズム。最適化問題において、厳密な解を求めることが不可能な場合、あるいは現実的でない場合に、近似解を求めるアルゴリズムです。オペレーションズリサーチ、コンピュータサイエンス、エンジニアリングなどの分野でよく使用される。例として、貪欲アルゴリズムやシミュレーテッドアニーリングなどがある。
アルゴリズムには、暗号化アルゴリズム、圧縮アルゴリズム、暗号化アルゴリズムなど、他にも多くの種類があります。
ソーシャルメディアプラットフォームは、このアルゴリズムをどのように利用しているのでしょうか?
ソーシャルメディアプラットフォームは、より効果的なアプローチのために、これらのアルゴリズムを組み合わせて使用することができることに注意することが重要です。さらに、各アルゴリズムの有効性は、特定の状況や実装方法によって異なります。また、ソーシャルメディア企業は、パフォーマンスとユーザー体験を向上させるために、これらのアルゴリズムを定期的に更新し、改善しています。
これらのアルゴリズムは、プラットフォームを支援します。
- コンテンツの推薦。ユーザーの興味やプラットフォーム上での行動に基づいて、アルゴリズムがコンテンツを推薦する。これには、友人やフォローしているページからの投稿や、アルゴリズムがユーザーの興味を引くと判断した投稿が含まれることがある。
- ニュースフィードのキュレーション。ユーザーのニュースフィードに表示される投稿の順番をアルゴリズムで決定します。アルゴリズムは、投稿の関連性、ユーザーの過去の類似コンテンツとのインタラクション、投稿が行われた時間などの要素を考慮する。
- 検索。アルゴリズムは、検索結果を関連性に基づいてランク付けすることで、ユーザーがプラットフォーム上でコンテンツを見つけるのを助ける。
- トレンドアルゴリズムがプラットフォーム上で人気のあるトピックやトレンドをリアルタイムで特定し、ユーザーにハイライト表示します。
- 広告のターゲティング。ユーザーの興味やプラットフォーム上での行動に基づいて、アルゴリズムが広告をマッチングさせる。
- コンテンツのフィルタリング。ヘイトスピーチ、ハラスメント、誤報など、プラットフォームのコミュニティガイドラインに反するコンテンツをアルゴリズムでフィルタリングする。
- モデレーションコミュニティガイドラインに反するコンテンツに対して、アルゴリズムがフラグを立て、報告し、削除します。
- パーソナライゼーション。アルゴリズムは、プラットフォーム上のユーザーの体験をパーソナライズします。これには、特定のデモグラフィック、興味、または行動をターゲットにすることが含まれます。
ミーム
次は、アルゴリズムが活躍する「ミーム」です。
ミームとは?
リチャード・ドーキンスは1976年に出版した著書"利己的な遺伝子ミームとは、インターネットを通じて急速に広まる文化的要素を表す造語で、テキストやキャプション付きの画像やビデオの形で使われることが多い。ミームは、人気のある映画やテレビ番組、その他のインターネット上のミームを参照する、喜劇的な性質を持つこともあります。ミームは、風刺や社会批判として、文字通り誰にでも作られ、共有されます。ミームは、共通の理解やユーモアを通じて人々をつなぎ、インターネット文化の重要な部分を担っています。
人気のミーム
人気のあるものをいくつか紹介します。
- "Harambe"(2016年)-シンシナティ動物園で子供が囲いの中に落ち、射殺されたゴリラである。このミームでは、懐かしさや喪失感を表現するために、ハランベの名前がよく登場します。
- "Doge"(2013年) - 柴犬の犬にカタコトの英語とComic Sansフォントで書かれたキャプション。このミームには、"such wow" や "very [adjective]" などのフレーズがよく登場します。
- "Distracted Boyfriend" (2017) - 恋人が不服そうに見ている中、他の女性を見ている男性のストックフォトです。人々はこのミームを使用して、不倫や裏切りの問題についてコメントします。
- "Expanding Brain" (2016) - 脳が大きくなっていくイメージに、知能レベルの上昇を説明する様々なキャプションが添えられています。
- "Mocking SpongeBob" (2017) - アニメシリーズ「スポンジ・ボブ」のスポンジ・ボブの絵に、あざとい口調で書かれたテキストを添えました。
- 「Pepe the frog" (2005) - 4chanや他のオンラインプラットフォームで人気を博したインターネットミーム。このミームは通常、ペペの写真とカタコトの英語で書かれたキャプションで構成されている。
- "Dank Memes"(2015年)-特に面白い、あるいは賢いとされるミームは "Dank Memes "と呼ばれます。
- "Moth Meme" (2018) - ランプに向かって飛ぶ蛾の絵は、何かに惹かれる人を、しばしばユーモアや皮肉で表現しています。
- "Baby Yoda" (2019) - Disney+シリーズ「The Mandalorian」のキャラクターで、すぐに人気が出てミームで広く使われるようになりました。
- "Arthur Fist" (2018) - 子供向け番組「アーサー」のキャラクター・アーサーが、一般的に決意や怒りを表すときに使われる拳を作っている画像です。
あなたにぴったりのミームを提供
適切なミームを提供するために、ソーシャルメディアプラットフォームは、決定木で動作するアルゴリズムを使用しています。決定木アルゴリズムは、機械学習アルゴリズムの一種であることは前述したとおりです。
入力された変数を使って、好みや閲覧履歴など関連するデータ群を分析し、どのミームに興味を持つか予測します。
このアルゴリズムは、決定と結果のツリー状構造を作成し、各内部ノードが入力変数をテストし、各枝がテストの結果を表し、各葉ノードが予測された結果またはクラスを表します。アルゴリズムはルートノードから始まり、最終的な予測を表すリーフノードに到達するまで、入力変数に基づく決定を行うことでツリーを横断する。
アルゴリズムが行う判断は、年齢、場所、閲覧履歴、以前に特定の種類のミーム(政治的ミーム、猫のミームなど)に興味を示したかどうかなどの要因に基づいて行われます。その後、アルゴリズムは、長さ、トーン、キーワードなど、ミームの特定の特徴に基づいて、さらに判断を行います。
決定木アルゴリズムは、その精度とロバスト性を向上させるために、他の機械学習技術と組み合わせて使用されることが多い。これにより、複雑なデータセットに基づく意思決定や、高い精度で結果を予測するための強力なツールとなります。
では、ストンとスクロールすると、どのように偏光が解消されるのでしょうか?
これはどういう仕組みなのか?もちろん、酔っていると、ご存知のように、笑いを誘う傾向が強くなります(そして、頭が悪くなる?)。でも、酔った状態で見るミームは、シラフで見るミームとは違うのです。
私の実験によると、酔った状態でのスクロールは、しらふの状態でのスクロールに比べ、より多くの笑いにつながることがわかりました。
その結果を、アルゴリズムで使われる決定木で可視化したのです。
ペギーは婚約しているのか?
このアルゴリズムが、何を見せるかを決定するための基本的な決定木を可視化すると、次のようになります。
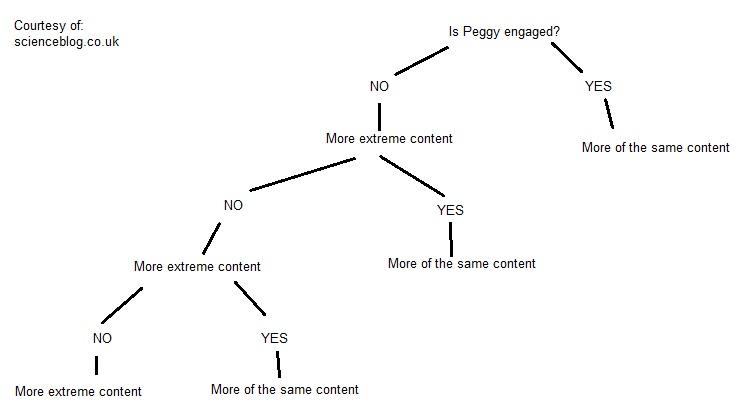
もし私がコンテンツに関与しなければ、アルゴリズムは、インタラクションが登録されるまで、より過激なコンテンツを提供し続けるのです。
この「より過激な」コンテンツは、プラットフォームが持つあなたのプロファイルに依存します。私のプロフィールは、次のようなものです。
20代のミレニアル世代のブロガーで、博士号を持ち、家を買おうとしているがうまくいかず、怒りや不満を受動的で攻撃的なソーシャルメディアの投稿やある種のミームを好きなことで発散している。
さて、このプロフィールは、私がそのソーシャルメディアプラットフォーム上で行ったすべての交流と情報に基づいています。
このプロファイルを使用することで、アルゴリズムが意思決定ツリーのどの時点でどのコンテンツを提供すれば、私の関心を引く可能性が高くなるかを決定するために使用するいくつかのカテゴリーを、私の意思決定ツリーにさらに記入することができるのです。
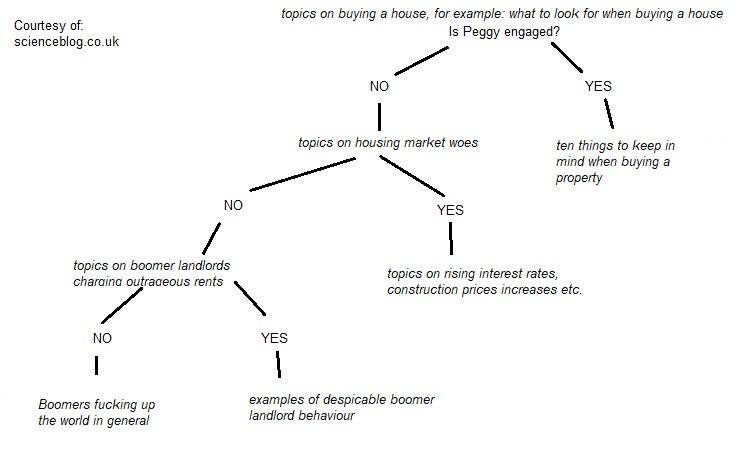
ミームの種類を変えても同じ決定木ができる。

もちろん、ソーシャルメディアプラットフォームが使用するアルゴリズムは、すべてのトピックを混ぜ合わせて、ユーザーの関心を集めようとしています。住宅市場に関するミームやトピックは、私が関心を持ち始めるまで流れていき、その時点でアルゴリズムが同じものをさらに提供することになります。しかし、決定木が深くなればなるほど、利用できるコンテンツは少なくなります。そのため、アルゴリズムは、私が関心を持ちそうな住宅市場に関する扇動的な(ブーマーに関連する)トピックを表示します。
心配しないで、幸せになってください
そして、たくさんのミームがあるため、アルゴリズムがより多くのミームを提供し続け、タイムラインをスクロールして笑いの渦に巻き込まれたのは、ソーシャルメディアを始めて以来初めてのことでした。このアルゴリズムはどんどん面白くなっている、ソーシャルメディア大好き!」と思いました。
しかし、実際は、より多くのコンテンツを持ち、よりシンプルで無邪気なものを笑うことで、アルゴリズムはよりソフトでグロッシーなコンテンツを提供し、ネット上の極論というウサギの穴に落ちないようにするのです。
今度、あなたがドゥームスクロールしているとき、実際には今のところ面白いと思っていないいくつかの間抜けなミームのように、宝石がすぐ近くで待っているかもしれないからです
「Fix Polarization: Start Scrolling Stoned.」への1件の返信
[…] When you think of algorithms, you’re probably thinking of Wall Street supercomputers whizzing around making thousands of calculations and transactions in a fraction of a second or social media companies monitoring your every click and comment, targeting you with ads and polarizing content. […]